Last Friday’s cluster &^%$ of IT outages plaguing companies globally will likely result in several billion dollars of economic impact. However, for CIOs, the problem wasn’t a security issue. Instead, this was an IT services management (ITSM) issue that caused massive disruption with companies relying on Microsoft’s Windows platform.
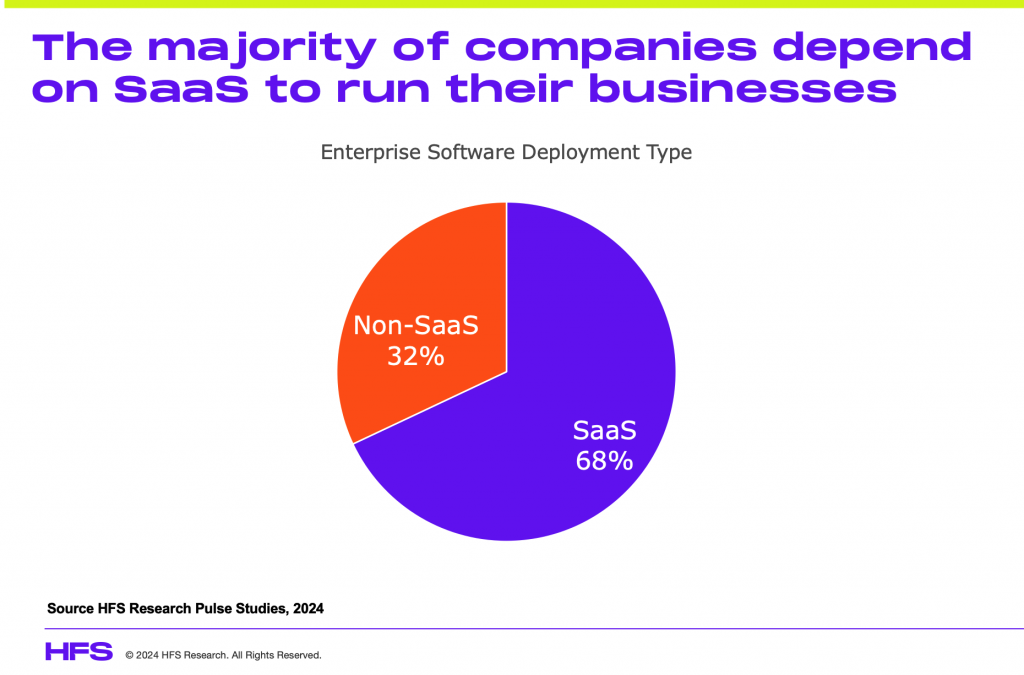
Software-as-a-service (SaaS) has become mainstream, with our research showing 68% of enterprise software is being delivered using this model today. As SaaS allows the software vendor to maintain, upgrade, and improve their solutions via their cloud delivery, updates are regularly issued as par for the course. However, as the CrowdStrike outages illustrate, many IT departments are getting too complacent, allowing their SaaS vendors to have full control of application management, updates, and automated delivery, especially when it comes to security updates. In addition, tech giants like Microsoft must be more diligent with their SaaS ecosystem partners.
This event happened as corporate IT has blindly trusted SaaS providers to patch their own solutions and assumed adequate testing and risk assessment
Friday, July 19th, wasn’t the first time there have been significant IT outages. For example, Rogers, the second largest telecom services provider in Canada, significantly impacted its customers in July 2022 with a router update from Cisco. And in 2020, SolarWind, another cybersecurity firm, dealt its customer a similar as their systems failed after an update. In the case of SolarWinds, this event has been traced back to a bad actor implanting malicious code in an update.
While companies depend on security patches to safeguard their systems, applications, and data, blindly trusting a loose federation of software companies to be mutually compliant is increasingly risky. Any IT leader worth their salt must have a process that not only governs software but also ensures that new software and patches have a modicum of testing to ensure compliance and stability. One only needs to crack open that dusty volume on the ITIL (Information Technology Infrastructure Library) framework to recant the importance of having a standardized process for quality assurance, testing, and deployment.
What caused the CrowdStrike mayhem was the release of a virus definition. Because the update is automated and is accepted automatically by its antivirus software, Flacon, when it was enabled, it caused the ‘blue screen of death’.
These automatic updates from SaaS vendors are common. However, EDR and antivirus firms push out a significant number of virus definition updates per week, sometimes even per day, depending on the severity of a virus they’ve discovered. This is all done to meet device-level security requirements required by standards like Soc2. However, when CrowdStrike released its version early Friday, July 19, it resulted in a global Windows meltdown for nearly every firm running CrowdStrike’s Falcon product.
CrowdStrike is a fault due to negligence processes
The ONLY explanation for this is CrowdStrike’s fundamental failure to follow basic ITSM or ITIL practices. ITIL is an industry recognized five step framework outlining a set of best practices and guidelines for managing and delivering IT software and services. ITIL offers software development teams with a systematic approach to IT service management (ITSM) with a focus on aligning their services with the needs of the business and ensuring the quality of the products they deliver.
In the case of CrowdStrike, its development team likely glossed over Step 3, Service Transition. While it likely focused on its standard operating procedure for writing the update the virus definition code, it appears they dropped the ball here for some unknown reason or hubris. As a reminder, in service transition, standard ITIL practices dictate the developer ensure the software (package, feature, or update) undergo a validation and test step. Surely, CrowdStrike has a stage gate for this, don’t they?
This step would have put the update through a quick battery of code testing, integration testing with Window’s OS, and finally system testing between the antivirus, Windows, and any additional services that might be called. Given the failure happened after the update hit the CrowdStrike Falcon software causing Windows clients globally to fail, it is pretty clear there was a lack of quality or system testing prior to release.
Therefore, one can only assume that CrowdStrike’s developers make the poor decision to skip testing and trust that their update would just work. This is a black mark on CS’s quality control, assuming it has one, and should lead to many CIO asking their CrowdStrike rep, “WTF, don’t you test these?!”
As an aside, this isn’t first time this has happened under the watch of the CEO of CrowdStrike, so this is likely to be an endemic issue with Crowdstrike’s internal processes.
This fiasco not Microsoft’s direct fault, but it does highlight weaknesses in its SaaS ecosystem
This outage has nothing to do with Microsoft, per se, even though Microsoft has had similar issues with the malformed Microsoft Defender antivirus updates that have disabled users’ computers in the past.
Yet, while not a Microsoft-caused issue, Microsoft must revisit how SaaS developers are allowed to release software in their ecosystem. Given the brand damage and potential legal and regulatory suits that will emerge from this, it is likely, but should never be assumed, that Microsoft will need to review its partner program.
In this review, Microsoft’s partner program must revise how its ecosystem will be regulated and held accountable for any damage-causing economic events of varying magnitude. The highest, and arguably the one that CrowdStrike reached this past week, may result in its partnership being revoked. While adding additional stage gates may slow down delivery, innovation, and services, the vendor may have to implement stringent guidelines as not doing so makes it culpable for not ensuring its partners are accountable for their products having a detrimental impact on its customers.
So what is next for the world of SaaS and cyber?
The global outages caused by a CrowdStrike update could have been mitigated had it followed ITIL. Basic ITIL procedures dating back over several decades implore responsible testing prior to a release.
While CrowdStrike took down global operations for millions of firms with a malformed virus definition as part of an automated update to its ESR clients, it is still culpable for not testing. This negligence should be the focus of many companies and lawyers.
And while this (hopefully) will be a one-time event for the vendor, the damage done was nearly catastrophic. The result is a significant erosion of trust between CrowdStrike and its customers. But we can’t just blame CrowdStrike, we signed agreements that have allowed this to happen.
Nonetheless, we are fools if we don’t learn from this event. As such, every CIO must revisit the policies and procedures for accepting updates from their SaaS and applications vendors. This will be an extensive list that will stretch from Microsoft’s Windows updates to SAP. Through this exercise, the CIO must come to an understanding of which vendors may have a material impact on their firm’s ability to function.
While HFS isn’t advocating that the CIO adopt a manual review of any patches or updates, for that would be a fool’s errand. Rather, we recommend that a firm’s IT leadership, and if they have one of their managed services providers, take stock of the enterprise user license agreements (EULA), who owns the risk, and what terms of service may require updating given the risk or impact any similar outage may cause in the future.
As many are likely to discover, it is unlikely the CIO, CEO, or chief legal officer will have much ground to stand on with CrowdStrike after this event. But to remain complacent towards future events is negligent. After all, what responsible firm will trust its supply chain (tech or non-tech) to make changes to solutions that may render your systems inoperable? There must be a ‘trust but verify’ program that ensures that activities originating outside their IT organization must have followed some process for approval/staging/release gate prior to widespread deployment inside of the organization.
Expect another week of upcoming chaos and fallout.
The extent of this outage puts a lot of pressure on corporate IT and their services partners to reset computers and implement the fixes. With computers supporting systems, it’s likely that many, but unfortunate not all, end-point devices can be fixed remotely. This will require teams of experts to manually apply updates, reboot, and test systems.
The Bottom Line: The CrowdStrike event is the latest call to arms for your CIO to assign a team responsible for re-architecting your software and SaaS policies.
These new policies must prioritize operational resiliency and follow basic ITSM/ITIL best practices. We will be assessing the productivity, economic, and supplier impacts resulting from this CloudStrike event and how tech giants like Microsoft hold their SaaS ecosystems more accountable in future for this level of abject failure.
Posted in : Cybersecurity, SaaS, PaaS, IaaS and BPaaS, Security and Risk, Sourcing Best Practises, Uncategorized



